学习笔记深度学习基于 LeNet-5 的 MNIST 手写数字分类
小嗷犬介绍
环境准备
使用到的库:
安装:
Pytorch 环境配置请自行百度。
数据集介绍
使用 MNIST 数据集(Mixed National Institute of Standards and Technology database)。是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含 60,000 个示例的训练集以及 10,000 个示例的测试集。

下载地址: http://yann.lecun.com/exdb/mnist/
本文使用 Pytorch 自动下载。
网络模型介绍
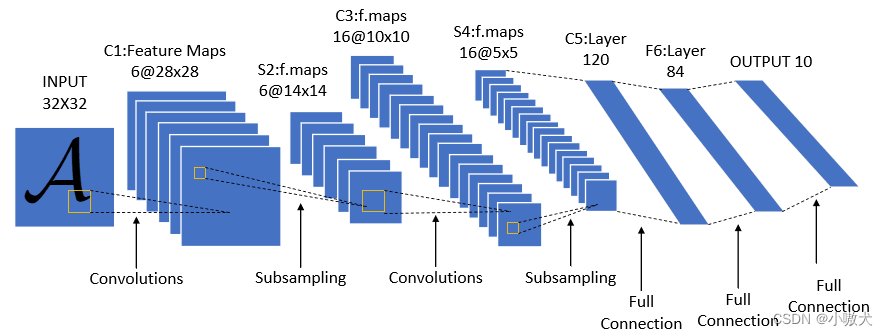
LeNet 是由 Yann Lecun 提出的一种经典的卷积神经网络,是现代卷积神经网络的起源之一。本文使用的 LeNet 为 LeNet-5。结构图如下:
导入相关库
1
2
3
4
5
| import torch
from torch import nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
|
定义 LeNet-5 网络结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class Reshape(nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28)
net = nn.Sequential(Reshape(), nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16*5*5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
|
下载并配置数据集和加载器
1
2
3
4
5
6
7
8
9
10
11
12
|
train_dataset = datasets.MNIST(root='./dataset', train=True,
transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./dataset', train=False,
transform=transforms.ToTensor(), download=True)
batch_size = 64
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size, shuffle=True)
|
定义损失函数和优化器
1
2
3
|
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters())
|
定义训练函数并训练和保存模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| def train(epochs):
for epoch in range(epochs):
for i, (images, labels) in enumerate(train_loader):
outputs = net(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 50 == 0:
print(
f'Epoch: {epoch + 1}, Step: {i + 1}, Loss: {loss.item():.4f}')
correct = 0
total = 0
for images, labels in test_loader:
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy: {correct / total * 100:.2f}%')
torch.save(net.state_dict(),
f"./model/LeNet_Epoch{epochs}_Accuracy{correct / total * 100:.2f}%.pth")
train(epochs=5)
|
可视化展示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def show_predict():
loader = DataLoader(dataset=test_dataset, batch_size=1, shuffle=True)
plt.figure(figsize=(8, 8))
for i in range(9):
(images, labels) = next(iter(loader))
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
title = f"Predicted: {predicted[0]}, True: {labels[0]}"
plt.subplot(3, 3, i + 1)
plt.imshow(images[0].squeeze(), cmap="gray")
plt.title(title)
plt.xticks([])
plt.yticks([])
plt.show()
show_predict()
|
预测图
结果来自训练轮数epochs=10,准确率Accuracy=98.42%的模型:
包含错误预测的结果:
加载现有模型(可选)
本文的训练函数会保存每次训练的模型,下一次预测可以不调用训练函数,而是直接加载已经保存的模型来进行预测:
1
2
|
net.load_state_dict(torch.load("./model/LeNet_Epoch10_Accuracy98.42%.pth"))
|
请根据自己的情况修改路径。