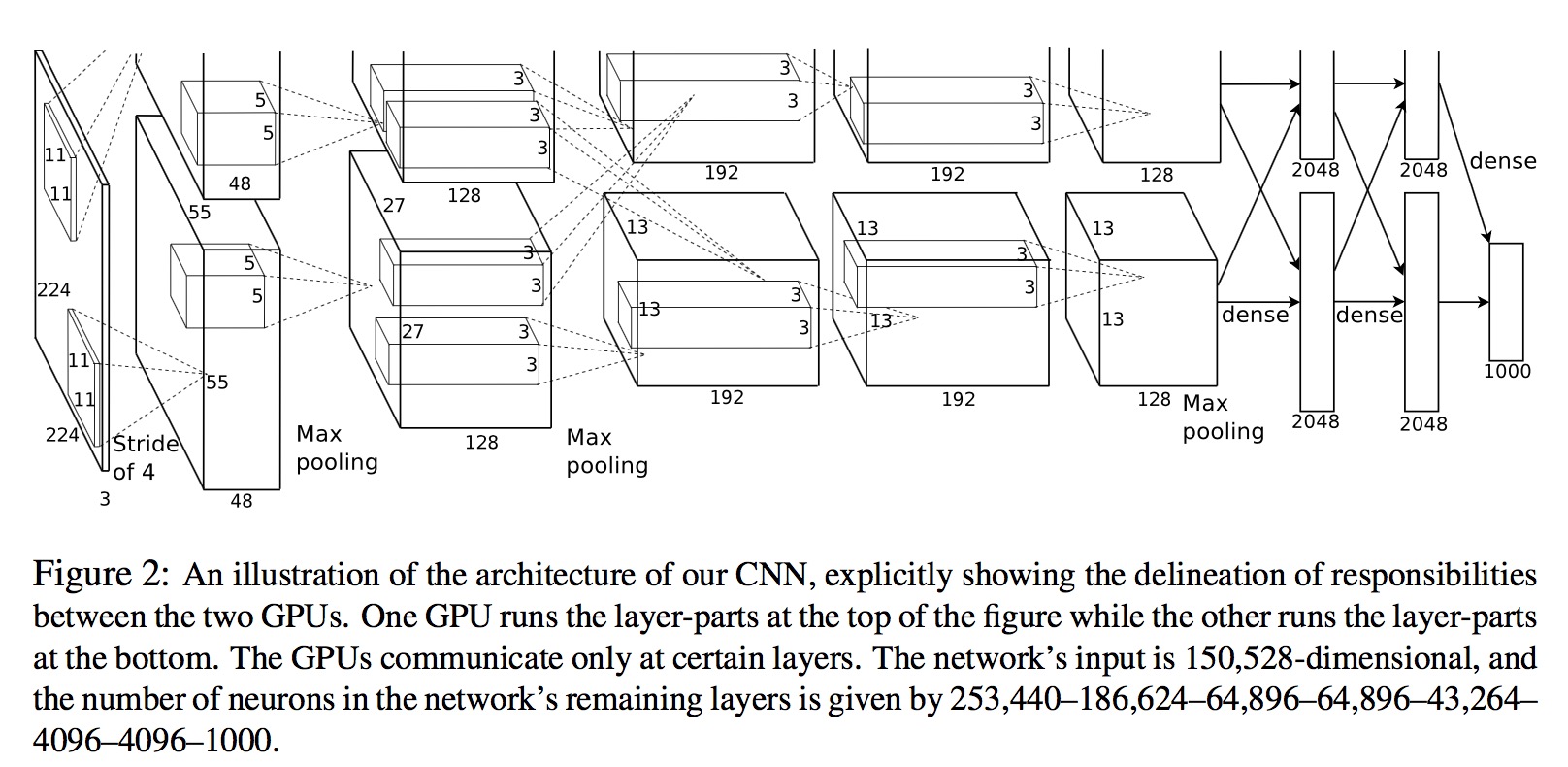
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| log_path = logger.log_dir + "/metrics.csv"
metrics = pd.read_csv(log_path)
x_name = "epoch"
plt.figure(figsize=(8, 6), dpi=100)
sns.lineplot(x=x_name, y="train_loss", data=metrics, label="Train Loss", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="val_loss", data=metrics, label="Valid Loss", linewidth=2, marker="X", markersize=12)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.tight_layout()
plt.show()
plt.figure(figsize=(14, 12), dpi=100)
plt.subplot(2,2,1)
sns.lineplot(x=x_name, y="train_acc", data=metrics, label="Train Accuracy", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="val_acc", data=metrics, label="Valid Accuracy", linewidth=2, marker="X", markersize=12)
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.subplot(2,2,2)
sns.lineplot(x=x_name, y="train_prec", data=metrics, label="Train Precision", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="val_prec", data=metrics, label="Valid Precision", linewidth=2, marker="X", markersize=12)
plt.xlabel("Epoch")
plt.ylabel("Precision")
plt.subplot(2,2,3)
sns.lineplot(x=x_name, y="train_recall", data=metrics, label="Train Recall", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="val_recall", data=metrics, label="Valid Recall", linewidth=2, marker="X", markersize=12)
plt.xlabel("Epoch")
plt.ylabel("Recall")
plt.subplot(2,2,4)
sns.lineplot(x=x_name, y="train_f1score", data=metrics, label="Train F1-Score", linewidth=2, marker="o", markersize=10)
sns.lineplot(x=x_name, y="val_f1score", data=metrics, label="Valid F1-Score", linewidth=2, marker="X", markersize=12)
plt.xlabel("Epoch")
plt.ylabel("F1-Score")
plt.tight_layout()
plt.show()
|